Funciones de cadena en SQL Server

En SQL Server, las funciones de cadena permiten manipular valores basados en cadenas de texto (incluyendo texto y alfanuméricos). También conocidas como “Funciones escalares de cadena”, las funciones de cadena toman uno o más valores de cadenas de texto como argumento y devuelven un valor de cadena modificado.
En SQL Server, cuando trabajamos con cadenas de texto, siempre debes usar comillas simples ' '. ¿Pero qué pasa si queremos incluir un carácter de comilla simple en el valor de la cadena? Bueno, en ese caso, debes escaparla duplicándola. Ejemplo:
1
SELECT 'Brian O''Conner' AS Nombre;
Resultado:
| Nombre |
|---|
| Brian O'Conner |
Usos principales de las funciones de cadena en T-SQL
Las funciones de cadena en SQL Server (Transact-SQL) son funciones escalares que operan sobre valores de tipo texto o que pueden convertirse a texto, y devuelven ya sea otra cadena o un número.
Estas funciones son fundamentales para:
- Limpiar o formatear datos de texto
- Extraer subcadenas
- Reemplazar o dividir texto
- Obtener la longitud o el valor numérico asociado a caracteres
- Realizar agregaciones agrupadas sobre texto, etc.
La documentación oficial lista varias funciones con distintos propósitos: manipulación sencilla de caracteres, búsqueda, transformación, agregación, y otras más especializadas.
| Función | Qué hace / uso principal |
|---|---|
ASCII | Devuelve el código ASCII del primer carácter de una cadena. |
CHAR | Devuelve el carácter correspondiente a un código ASCII. |
CHARINDEX | Devuelve la posición inicial de una subcadena dentro de otra cadena. |
CONCAT | Concatena dos o más cadenas en una sola. |
CONCAT_WS | Concatena valores usando un separador especificado. |
DIFFERENCE | Compara el valor SOUNDEX de dos cadenas y devuelve un número que mide su similitud fonética. |
FORMAT | Devuelve una cadena con formato de número o fecha. |
LEFT | Devuelve los primeros n caracteres de una cadena. |
LEN | Devuelve la longitud de una cadena (sin contar espacios finales). |
LOWER | Convierte una cadena a minúsculas. |
LTRIM | Elimina los espacios en blanco a la izquierda de una cadena. |
NCHAR | Devuelve el carácter Unicode correspondiente a un código entero. |
PATINDEX | Devuelve la posición inicial de un patrón dentro de una cadena. |
QUOTENAME | Devuelve una cadena delimitada con corchetes o comillas dobles. |
REPLACE | Reemplaza todas las apariciones de una subcadena dentro de una cadena. |
REPLICATE | Repite una cadena un número especificado de veces. |
REVERSE | Devuelve la cadena en orden inverso. |
RIGHT | Devuelve los últimos n caracteres de una cadena. |
RTRIM | Elimina los espacios en blanco a la derecha de una cadena. |
SOUNDEX | Devuelve el código SOUNDEX de una cadena para comparaciones fonéticas. |
SPACE | Devuelve una cadena compuesta por un número especificado de espacios. |
STR | Convierte un valor numérico en una cadena con formato. |
STRING_AGG | Concatena valores de filas en una cadena con un separador. |
STRING_ESCAPE | Devuelve una cadena con caracteres escapados (JSON, etc.). |
STRING_SPLIT | Divide una cadena en filas, según un separador. |
STUFF | Inserta una cadena dentro de otra en una posición especificada. |
SUBSTRING | Devuelve una parte de la cadena, dada posición inicial y longitud. |
TRANSLATE | Sustituye caracteres específicos en una cadena según un mapeo. |
TRIM | Elimina espacios iniciales y finales de una cadena. |
UNICODE | Devuelve el código Unicode del primer carácter de una cadena. |
UPPER | Convierte una cadena a mayúsculas. |
Veamos un ejemplo sencillo usando la función UPPER, que convierte todo el texto a mayúsculas:
1
SELECT UPPER('hola mundo');
Ejercicios con funciones T-SQL de cadenas
Imaginemos que somos analistas de datos en Toretto’s Garage y necesitamos manipular y analizar información sobre el reparto y los vehículos de la primera película de Rápidos y Furiosos. Contamos con una base de datos que contiene información sobre los actores, personajes y sus icónicos vehículos.
Esquema de la base de datos Script - setup
1. CONCAT() - Concatenar cadenas
Combinar marca y modelo del vehículo:
1
2
3
4
SELECT
CONCAT(brand, ' ', model) AS vehiculo_completo,
year
FROM Vehicles;
Resultado:
| vehiculo_completo | year |
|---|---|
| Mitsubishi Eclipse | 1995 |
| Toyota Supra MK IV | 1994 |
| Nissan 240SX | 1993 |
| Acura Integra | 1990 |
| Honda S2000 | 2000 |
| Volkswagen Jetta | 1991 |
| Chevrolet S-10 | 1998 |
2. UPPER() y LOWER() - Mayúsculas y minúsculas
Mostrar nombres en mayúsculas y vehículos en minúsculas:
1
2
3
4
5
6
7
SELECT
UPPER(actor_name) AS actor_mayusculas,
LOWER(character_name) AS personaje_minusculas,
brand,
model
FROM Cast c
INNER JOIN Vehicles v ON c.cast_id = v.cast_id;
Resultado:
| actor_mayusculas | personaje_minusculas | brand | model |
|---|---|---|---|
| VIN DIESEL | dominic toretto | Mitsubishi | Eclipse |
| PAUL WALKER | brian o’conner | Toyota | Supra MK IV |
| MICHELLE RODRIGUEZ | letty ortiz | Nissan | 240SX |
| JORDANA BREWSTER | mia toretto | Acura | Integra |
| RICK YUNE | johnny tran | Honda | S2000 |
| CHAD LINDBERG | jesse | Volkswagen | Jetta |
| MATT SCHULZE | vince | Chevrolet | S-10 |
3. LEN() - Longitud de cadenas
Analizar longitud de nombres y modelos:
1
2
3
4
5
6
7
8
9
SELECT
actor_name,
LEN(actor_name) AS longitud_nombre,
character_name,
LEN(character_name) AS longitud_personaje,
model,
LEN(model) AS longitud_modelo
FROM Cast c
INNER JOIN Vehicles v ON c.cast_id = v.cast_id;
Resultado:
| actor_name | longitud_nombre | Personaje | longitud_personaje | model | longitud_modelo |
|---|---|---|---|---|---|
| Vin Diesel | 10 | Dominic Toretto | 15 | Eclipse | 7 |
| Paul Walker | 11 | Brian O’Conner | 14 | Supra MK IV | 11 |
| Michelle Rodriguez | 18 | Letty Ortiz | 11 | 240SX | 5 |
| Jordana Brewster | 16 | Mia Toretto | 11 | Integra | 7 |
| Rick Yune | 9 | Johnny Tran | 11 | S2000 | 5 |
| Chad Lindberg | 13 | Jesse | 5 | Jetta | 5 |
| Matt Schulze | 12 | Vince | 5 | S-10 | 4 |
4. LEFT() y RIGHT() - Extraer subcadenas
Extraer primeras y últimas letras:
1
2
3
4
5
SELECT
actor_name,
LEFT(actor_name, 3) AS primeras_3_letras,
RIGHT(actor_name, 3) AS ultimas_3_letras
FROM Cast;
Resultado:
| actor_name | primeras_3_letras | ultimas_3_letras |
|---|---|---|
| Vin Diesel | Vin | sel |
| Paul Walker | Pau | ker |
| Michelle Rodriguez | Mic | uez |
| Jordana Brewster | Jor | ter |
| Rick Yune | Ric | une |
| Chad Lindberg | Cha | erg |
| Matt Schulze | Mat | lze |
5. SUBSTRING() - Extraer por posición
Extraer partes específicas de los nombres:
1
2
3
4
5
6
SELECT
actor_name,
SUBSTRING(actor_name, 1, 3) AS inicio_nombre,
character_name,
SUBSTRING(character_name, CHARINDEX(' ', character_name) + 1, LEN(character_name)) AS apellido_personaje
FROM Cast;
Resultado:
| actor_name | inicio_nombre | character_name | apellido_personaje |
|---|---|---|---|
| Vin Diesel | Vin | Dominic Toretto | Toretto |
| Paul Walker | Pau | Brian O’Conner | O’Conner |
| Michelle Rodriguez | Mic | Letty Ortiz | Ortiz |
| Jordana Brewster | Jor | Mia Toretto | Toretto |
| Rick Yune | Ric | Johnny Tran | Tran |
| Chad Lindberg | Cha | Jesse | Jesse |
| Matt Schulze | Mat | Vince | Vince |
Para extraer el apellido correctamente, usamos una combinación de varias funciones:
CHARINDEX(' ', character_name)Busca la posición del primer espacio en el nombre del personaje. Ejemplo: para'Dominic Toretto', devuelve8(el espacio entre “Dominic” y “Toretto”).CHARINDEX(' ', character_name) + 1Se suma 1 para empezar justo después del espacio, es decir, al inicio del apellido. Ejemplo:8 + 1 = 9→ posición de la “T” de “Toretto”.LEN(character_name)Devuelve la longitud total del nombre del personaje. Se usa como cantidad máxima de caracteres a tomar desde la posición indicada.
6. REPLACE() - Reemplazar texto
Reemplazar espacios por guiones:
1
2
3
4
5
SELECT
actor_name,
REPLACE(actor_name, ' ', '-') AS personaje_con_guiones,
REPLACE(character_name, ' ', '_') AS nombre_con_guion_bajo
FROM Cast;
Resultado:
| actor_name | personaje_con_guiones | nombre_con_guion_bajo |
|---|---|---|
| Vin Diesel | Vin-Diesel | Dominic_Toretto |
| Paul Walker | Paul-Walker | Brian_O’Conner |
| Michelle Rodriguez | Michelle-Rodriguez | Letty_Ortiz |
| Jordana Brewster | Jordana-Brewster | Mia_Toretto |
| Rick Yune | Rick-Yune | Johnny_Tran |
| Chad Lindberg | Chad-Lindberg | Jesse |
| Matt Schulze | Matt-Schulze | Vince |
7. CHARINDEX() - Encontrar posición
Encontrar posición del espacio en los nombres:
1
2
3
4
5
6
7
8
9
SELECT
actor_name,
CHARINDEX(' ', actor_name) AS posicion_espacio,
CASE
WHEN CHARINDEX(' ', actor_name) > 0
THEN LEFT(actor_name, CHARINDEX(' ', actor_name) - 1)
ELSE actor_name
END AS primer_nombre
FROM Cast;
Resultado:
| actor_name | posicion_espacio | primer_nombre |
|---|---|---|
| Vin Diesel | 4 | Vin |
| Paul Walker | 5 | Paul |
| Michelle Rodriguez | 9 | Michelle |
| Jordana Brewster | 8 | Jordana |
| Rick Yune | 5 | Rick |
| Chad Lindberg | 5 | Chad |
| Matt Schulze | 5 | Matt |
8. LTRIM() y RTRIM() - Eliminar espacios
Limpiar espacios en blanco:
1
2
3
4
5
6
7
8
9
10
11
12
WITH DatosProcesados AS (
SELECT
actor_name,
CONCAT(' ', actor_name, ' ') AS nombre_con_espacios
FROM Cast
)
SELECT
actor_name,
nombre_con_espacios,
LTRIM(RTRIM(nombre_con_espacios)) AS nombre_limpio
FROM DatosProcesados;
Resultado:
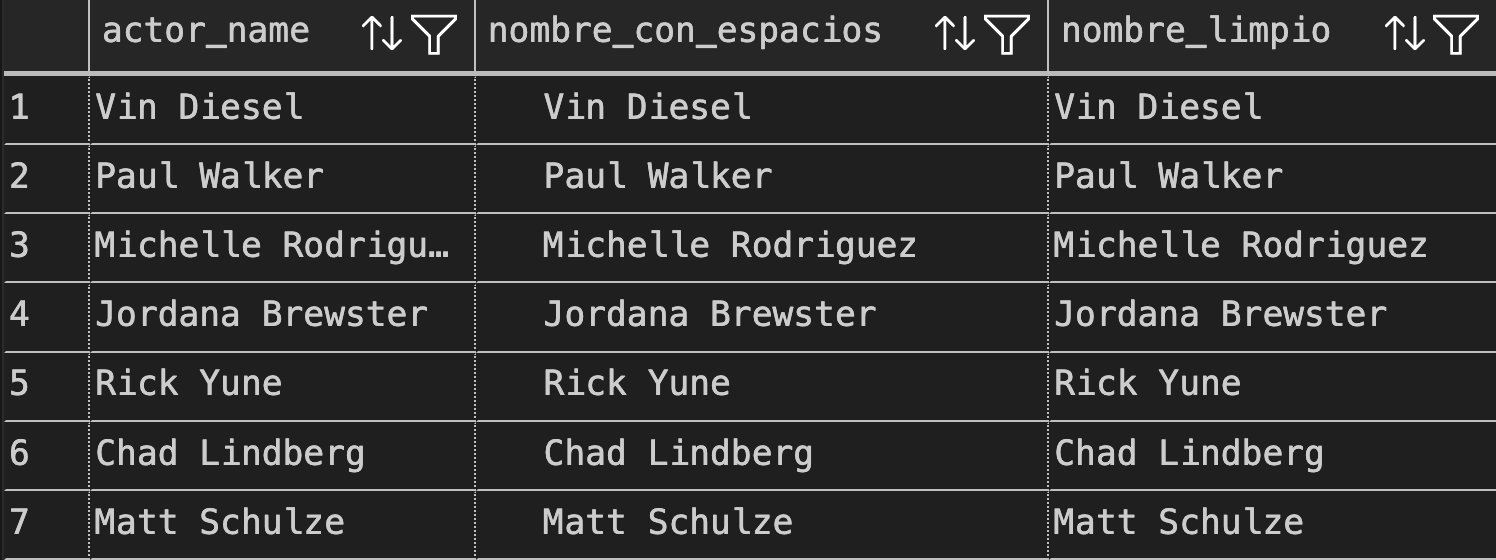
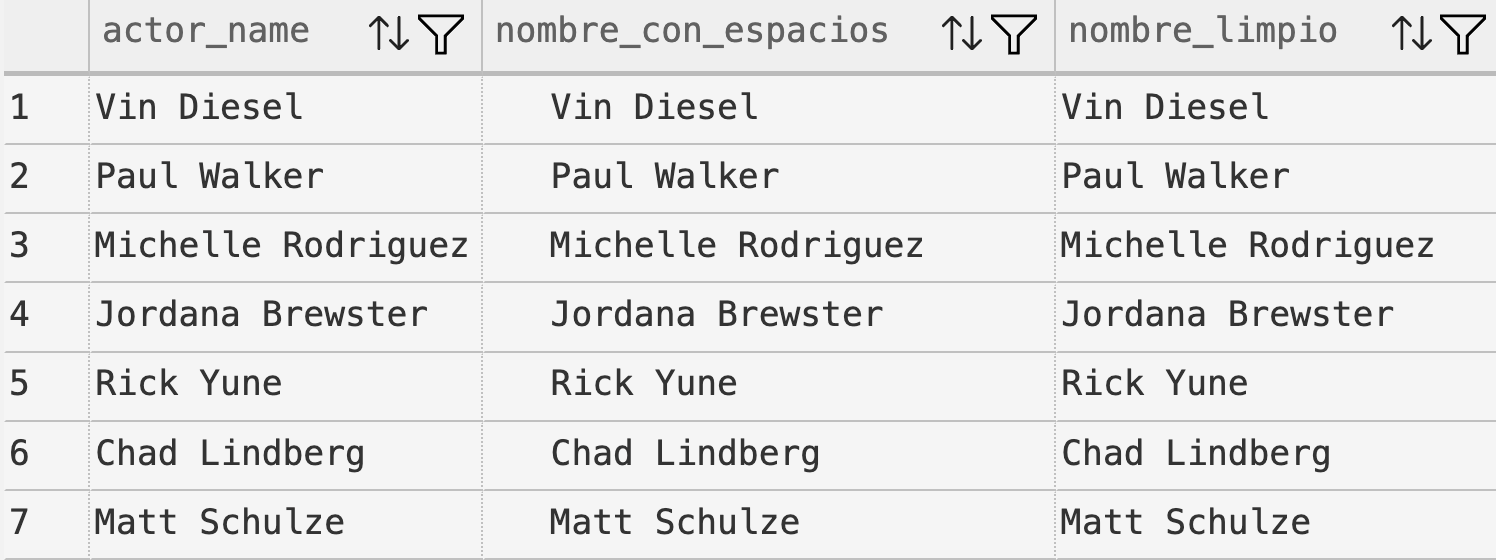
Usamos
WITH(CTE - Common Table Expression) para crear una tabla temporal lógica que organiza el código en etapas para separar claramente la preparación de datos (agregar espacios) de la transformación (eliminar espacios).
9. STRING_AGG() - Agrupar cadenas (SQL Server 2017+)
Agrupar todos los modelos de vehículos por marca:
1
2
3
4
5
6
7
8
9
10
11
12
-- Añadimos más vehículos por marca para ver mejor el resultado
INSERT INTO Vehicles (cast_id, brand, model, year) VALUES
(2, 'Toyota', 'Celica', 1999),
(2, 'Toyota', 'MR2', 1990),
(5, 'Honda', 'Civic', 2000),
(5, 'Honda', 'Prelude', 1995);
SELECT
brand,
STRING_AGG(model, ', ') AS modelos_agrupados
FROM Vehicles
GROUP BY brand;
Resultado:
| brand | modelos_agrupados |
|---|---|
| Acura | Integra |
| Chevrolet | S-10 |
| Honda | Civic, Prelude, S2000 |
| Mitsubishi | Eclipse |
| Nissan | 240SX |
| Toyota | Supra MK IV, Celica, MR2 |
| Volkswagen | Jetta |
Las funciones de cadena en SQL Server son esenciales para manipular y transformar datos textuales. En nuestro escenario práctico, hemos visto cómo aplicar estas funciones para:
- Formatear nombres y modelos de vehículos
- Extraer información específica de cadenas
- Crear identificadores únicos
- Limpiar y estandarizar datos
Estas habilidades son cruciales para cualquier profesional que trabaje con bases de datos, permitiendo transformar datos crudos en información valiosa y bien estructurada.

¡Recuerda! La familia no son solo los que comparten tu sangre, sino también los que dominan las funciones de cadena en SQL. ❤️